Objective 11b) Naughty/Nice List with Blockchain Investigation Part 2
The SHA256 of Jack's altered block is: 58a3b9335a6ceb0234c12d35a0564c4e f0e90152d0eb2ce2082383b38028a90f. If you're clever, you can recreate the original version of that block by changing the values of only 4 bytes. Once you've recreated the original block, what is the SHA256 of that block?
Now this challenge was nuts. The foundation of this is understanding Hash Collisions and how they can be used to an attacker's advantage. The story here is we have reason to believe that Jack Frost may have modified the blockchain to bolster his numbers considerably on Santa's naughty/nice blockchain. Since the enter concept of a blockchain is for each block to validate the block prior to it, a simple modification to an item within the blockchain will change the resulting hash of the block, every single block after the changed block will have a different hash, and thus invalidate the blockchain. This entire concept of preservation is what allows a blockchain to retain its history.
Finding Jack Frost in a Sea of Blocks
And yet, somehow, Shinny Upatree, the assigned elf to review Jack Frost, claims that he never wrote the document linked to Jack Frost's account, and for some reason Jack's "Nice" score was incredibly high! Some strange treachery was afoot, and if I'm going to start somewhere, it's probably to find the block associated with Jack Frost. Luckily the way to find that is essentially to compare the provided SHA256 hash at the top of this page (58a3b9335a6ceb0234c12d35a0564c4e f0e90152d0eb2ce2082383b38028a90f) with each resulting block. And since the blockchain doesn't use SHA256, it seems I'm going to have to hash each and every block and compare it with what I know to find the block number. To accomplish this, I used python!
#!/usr/bin/python3
from naughty_nice import *
import hashlib
# First, import the blockchain
c = Chain(load=True, filename='blockchain.dat')
compare_hash = '58a3b9335a6ceb0234c12d35a0564c4ef0e90152d0eb2ce2082383b38028a90f'
for i, block in enumerate(c.blocks):
my_hash = hashlib.sha256(block.block_data_signed()).hexdigest()
if my_hash == compare_hash:
print(f"Found match at index: {block.index}, at list # {i}!")
print("Dumping file contents...")
for i in range(block.doc_count):
block.dump_doc(i)
break
Running that prints:
┌─[agr0@spicytaco]─[~/Documents/HHC/blockchain/]
└──╼ $ python3 ./get_altered.py
Found match at index: 129459, at list # 1010!
Dumping file contents...
Document dumped as: 129459.pdf
Document dumped as: 129459.bin
So now I have the block in question, which I can access at c.blocks[1010], and it contains the contains the following:
Chain Index: 129459
Nonce: a9447e5771c704f4
PID: 0000000000012fd1
RID: 000000000000020f
Document Count: 2
Score: ffffffff (4294967295)
Sign: 1 (Nice)
Data item: 1
Data Type: ff (Binary blob)
Data Length: 0000006c
Data: b'ea465340303a6079d3df2762be68467c27f046d3a7ff4e92dfe1def7407f2a7b73e1b759b8b919451e37518d22d987296fcb0f188dd60388bf20350f2a91c29d0348614dc0bceef2bcadd4cc3f251ba8f9fbaf171a06df1e1fd8649396ab86f9d5118cc8d8204b4ffe8d8f09'
Data item: 2
Data Type: 05 (PDF)
Data Length: 00009f57
Data: b'255044462d312e330a2525c1cec7c5210a0a312030206f626a0a3c3c2f547970652f436174616c6f672f5f476f5f417761792f53616e74
<< snip >>
93ec8d21c07d86032d97df517106022db0c21c33c03402019a43'
Date: 03/24
Time: 13:21:41
PreviousHash: 4a91947439046c2dbaa96db38e924665
Data Hash to Sign: 347979fece8d403e06f89f8633b5231a
Signature: b'MJIxJy2iFXJRCN1EwDsqO9NzE2Dq1qlvZuFFlljmQ03+erFpqqgSI1xhfAwlfmI2MqZWXA9RDTVw3+aWPq2S0CKuKvXkDOrX92cPUz5wEMYNfuxrpOFhrK2sks0yeQWPsHFEV4cl6jtkZ//OwdIznTuVgfuA8UDcnqCpzSV9Uu8ugZpAlUY43Y40ecJPFoI/xi+VU4xM0+9vjY0EmQijOj5k89/AbMAD2R3UbFNmmR61w7cVLrDhx3XwTdY2RCc3ovnUYmhgPNnduKIUA/zKbuu95FFi5M2r6c5Mt6F+c9EdLza24xX2J4l3YbmagR/AEBaF9EBMDZ1o5cMTMCtHfw=='
This is it! This is Jack's official block within the blockchain! You can see a couple of things, first of all his score is "ffffffff" or "4294967295." I don't know the scoring mechanism for Naughty or Niceness scaling, but that seems fairly excessive. Also, there are two files associated with his account: A PDF file and a .bin file. The bin file just seems like it's junk, as file shows that it's just regular old data and no strings can be pulled from it, but the PDF file sure looked suspicious:

First of all, come on Tooth Fairy! You were the bad guy last year! That's suspicious enough if you ask me.
But what's up with this? This actually validates? Something is messed up here...and luckily I have resources to review it.
MD5 is Dead!
MD5 is a pretty popular hashing algorithm, mostly because of it's simplicity. You want to check the hash of a file to compare it to another copy you have on another machine, no big deal, you run md5sum on the file and it spits out a 32-character hex string, albeit a 16-byte number. It's a hash that is small enough to work with and you don't really think much of it. Who cares, right? Just MD5 hash any blob of data and it will spit out a [supposedly] unique value that you can use to compare or at least save and use to make sure the file has not been modified since your last check.
However, there is always a possibility that two hashes of two completely separate blobs of data can result in the exact same hash. It has to be the case, considering no matter what you run through the MD5 hashing algorithm, it will always output a 16-byte number. The file you use can be either a 200TB file or a 2 kilobyte file, if run through the MD5 hash, it will output to a 16 byte number. Therefore, there are only so many possible combinations of numbers that can result from the hash. Eventually, given enough iterations, the resulting hash will start repeating. This repetition is called a hash collision. It's rare enough for it to happen, but is it really? That's what this challenge is here to find out.
Based on this talk from Ange Albertini, and probably even better, this is a talk from the same author, there are a few things to take from this. I can abridge this only so much, if this is of any interest to the reader I implore you to watch this in its entirety, but the gist of it is:
- MD5 is very much dead. It is almost too easy to generate a collision.
- Generating a collision involves Adding 1 to a byte by the block boundary (more on this later), and subtracting 1 from the same byte at the next block
- The above is called a Unicoll Collision. And the basics of that:

I should note here that unicoll doesn't mean that every single 10th character can be modified...but before I go into that I'd like to go into how hashes work.
Hashes and YOU
When a hash is computed on a blob of data, the way it works is that the hash algorithm works on blocks at a time, not unlike encryption. In the case of MD5, it works on blocks of 64 bytes at a time. And the way that it works is thus:
- On the first 64 bytes of data, it runs a computation of the data with a set static number. The result will always be 16 bytes long. Fun fact, the static number that MD5 initializes with is:
word A: 01 23 45 67
word B: 89 ab cd ef
word C: fe dc ba 98
word D: 76 54 32 10
- On the second 64 bytes of data, it runs the computation of the data with the result of the previous computation.
- This process repeats until it hits a block that is less than 64 bytes, in which case it pads the data until it hits 64 bytes. It then finishes the hash and spits out a 16 byte number.
So you can see that there are 'boundaries' within MD5. Each blob of data is chopped up into 64-byte blocks, and ended with padding. And based on this:



Interesting...so there exists a possibility that you could change data within a block by adding 1 to it, as long as you subtract 1 from the next block in the same position, which in this case would be 64 bytes later.
This is good information to know! But how can this be utilized in this scenario?
PDF Headers
A PDF can be modified considerably by only modifying a few bytes at a time! For example, as explained on this github link, a PDF has some interesting points to recognize:
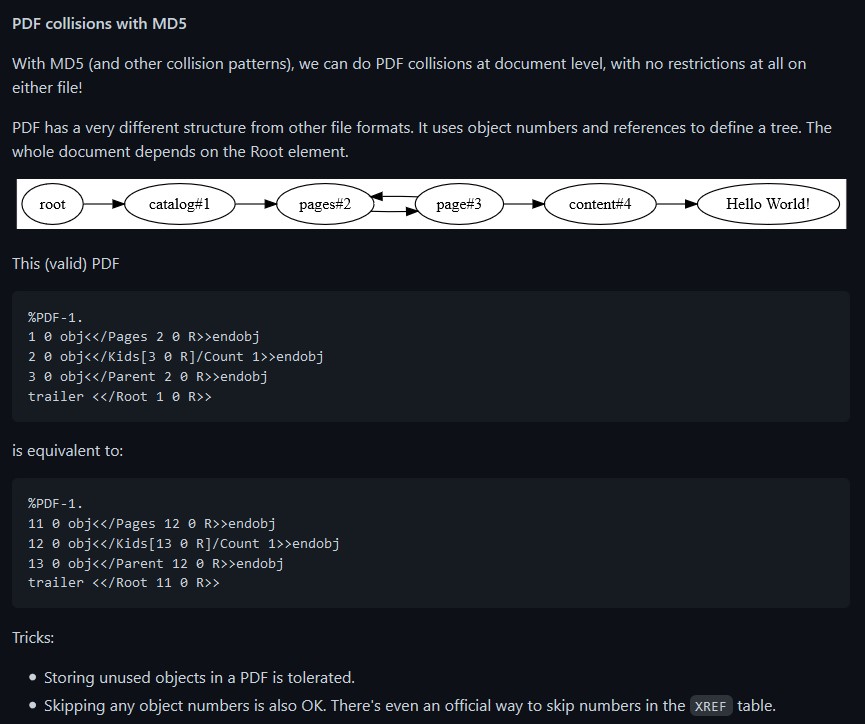
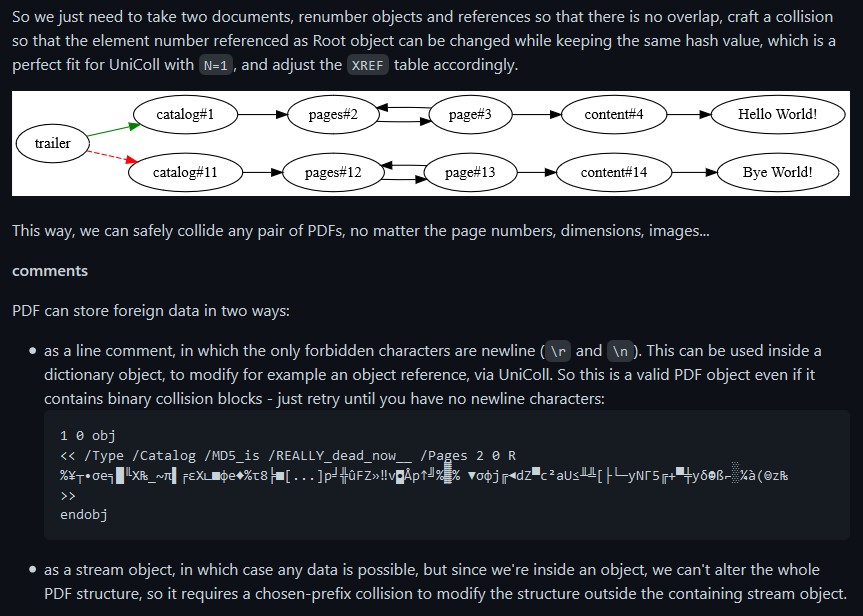
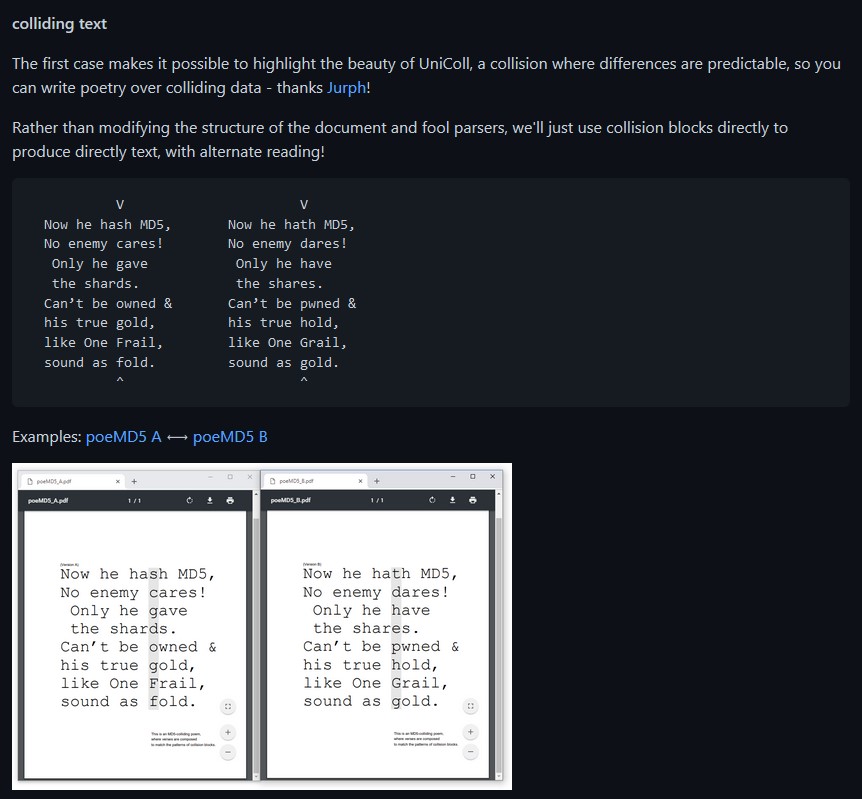
So...what the above basically says is that there exists a possibility that a PDF file can have data inside of it that is effectively hidden, simply by modifying a single byte. And that byte can be something as "insignificant" as just the Page number mentioned in the header block of the PDF file itself. Now...I have a PDF file listed in Jack Frost's block within the blockchain...let's take a look at the file header there:
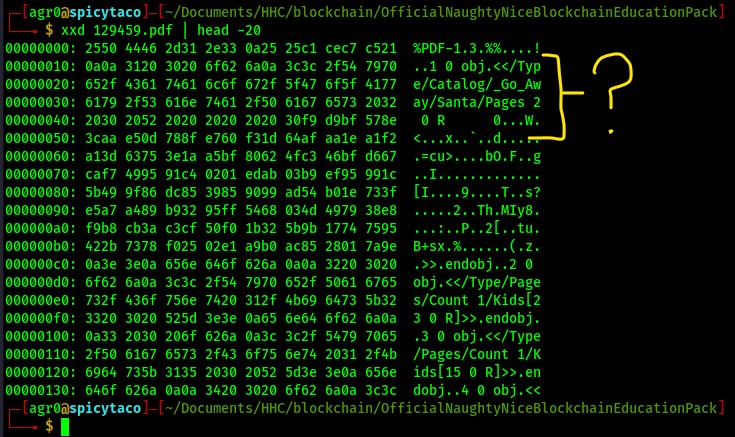
Well that's interesting.../Type/Catalog/_Go_Away/Santa/Pages 2? Based on the above...just for yuks, what happens if I change the Pages 2 to something like... Pages 3?
I can edit it with a hexeditor:
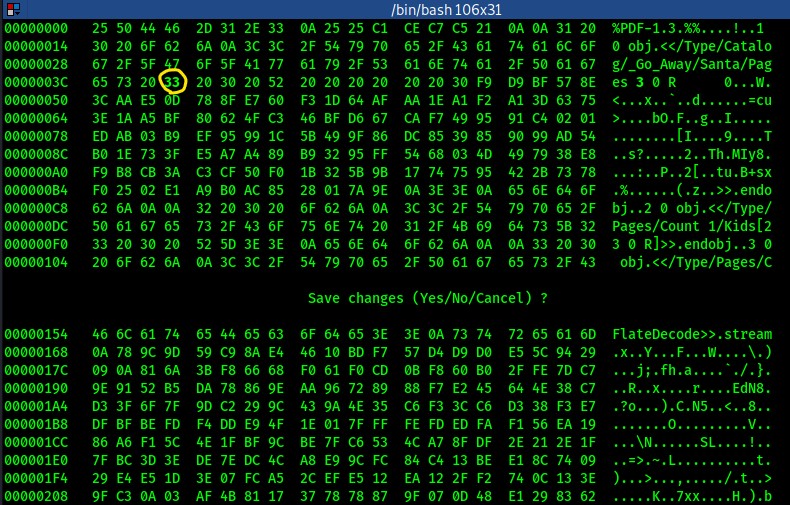
And then opening the PDF:

Look at that! A whole other PDF!
New Stuff has Come to Light, Dude
The additional data we recovered from the PDF seems particularly interesting...this seems like the document that Shinny Upatree actually wrote!
I can take a few things from the above: - Jack apparently is a tremendous jerk, enough to warrant a really high score on the naughty list, and yet he's listed as nice. His score is most likely negated! - Jack crafted a PDF first and let Shinny modify it, presumably to write the above newly-found document, but made a simple change to flip the contents considerably. - Jack told Shinny to basically give him the worst score possible.
That seems particularly interesting...so what can I gather from this? I only need to modify 4 bytes, and I see that I can modify the page number by adding 1 to it, so clearly this must be one of the four bytes I'll need to modify.
However, what about Jack's Naughty/Nice score? Jack's "Sign" bit is set to 1, which is considered "Nice," but it's a binary flag. I can modify that to 0 by subtracting 1 to it however, which enumerates to "Naughty," and that falls in line pretty well with someone that travels to Australia to kick a caged wombat. Incidentally, I don't think I could have ever predicted I would type that sentence in any context.
Putting it All Together
So as of right now, we're 2 for 4 of the bytes we need to modify. There is the byte in the PDF referring to the page to display (in which we changed it from Page 2 to Page 3), and there is the Naughty/Nice bit that we flipped, negating Jack's "Nice" status to "Naughty." So what about the other two?
As it turns out, I already mentioned them. I posted this:
The basic idea here is that Jack found a way to create a collsion, and used a Unicoll attack on the data at two separate points within the block that worked to his favor: the naughty/nice bit and the PDF page. But in order for Unicoll to work, for whatever byte that he managed to add or subtract one from/to, he had to add or subtract one from the corresponding byte 64 bytes later in the block. For example:
Say Jack has this blob of data of arbitrary values:
01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F 10
11 12 13 14 15 16 17 18 19 1A 1B 1C 1D 1E 1F 20
21 22 23 24 25 26 27 28 29 2A 2B 2C 2D 2E 2F 30
31 32 33 34 35 36 37 38 39 3A 3B 3C 3D 3E 3F 40
41 42 43 44 45 46 47 48 49 4A 4B 4C 4D 4E 4F 50
51 52 53 54 55 56 57 58 59 5A 5B 5C 5D 5E 5F 50
Jack wants to utilize a Unicoll collision on the 10th byte within the block,
and each block (as far as MD5 is concerned anyway) is 64 bytes in length. So
in order for Jack to create different data that hashes to the same result, he
needs to first add 1 to the 10th block:
01 02 03 04 05 06 07 08 09*0B*0B 0C 0D 0E 0F 10
11 12 13 14 15 16 17 18 19 1A 1B 1C 1D 1E 1F 20
21 22 23 24 25 26 27 28 29 2A 2B 2C 2D 2E 2F 30
31 32 33 34 35 36 37 38 39 3A 3B 3C 3D 3E 3F 40
41 42 43 44 45 46 47 48 49 4A 4B 4C 4D 4E 4F 50
51 52 53 54 55 56 57 58 59 5A 5B 5C 5D 5E 5F 50
However, in order for Jack to validate the data to the exact same hash result,
Jack needs to SUBTRACT 1 from the corresponding byte 64 bytes AFTER!
01 02 03 04 05 06 07 08 09*0B*0B 0C 0D 0E 0F 10
11 12 13 14 15 16 17 18 19 1A 1B 1C 1D 1E 1F 20
21 22 23 24 25 26 27 28 29 2A 2B 2C 2D 2E 2F 30
31 32 33 34 35 36 37 38 39 3A 3B 3C 3D 3E 3F 40
41 42 43 44 45 46 47 48 49*49*4B 4C 4D 4E 4F 50
51 52 53 54 55 56 57 58 59 5A 5B 5C 5D 5E 5F 50
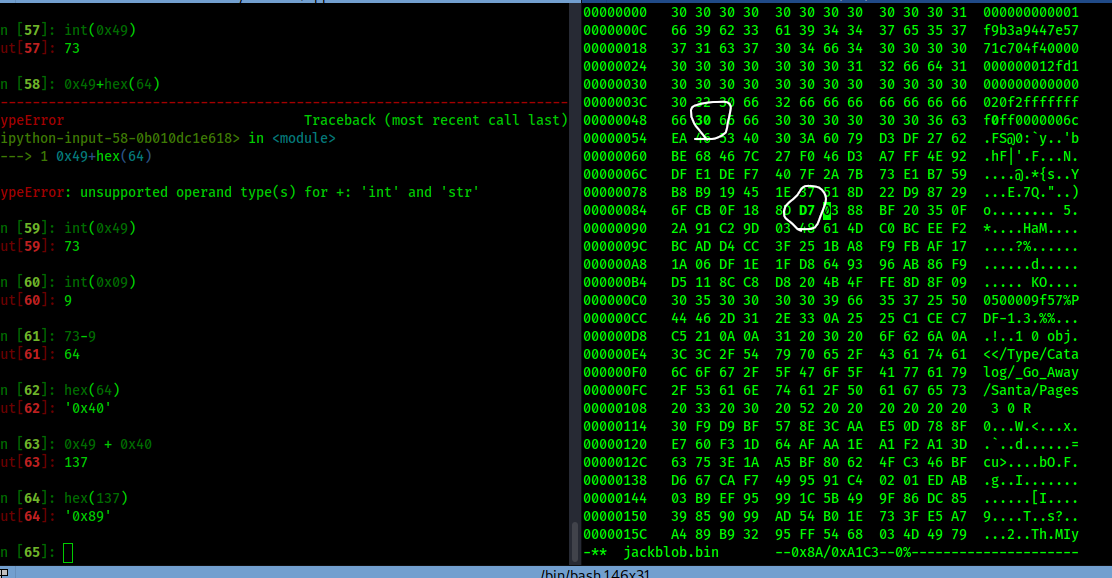
Therefore, since I subtracted 1 from the value of the Naughty/Nice byte (to flag him as Naughty instead), I had to add 1 to the corresponding byte 64 bytes after.
First, the Naughty/Nice byte, complete with me using python for some calculations:
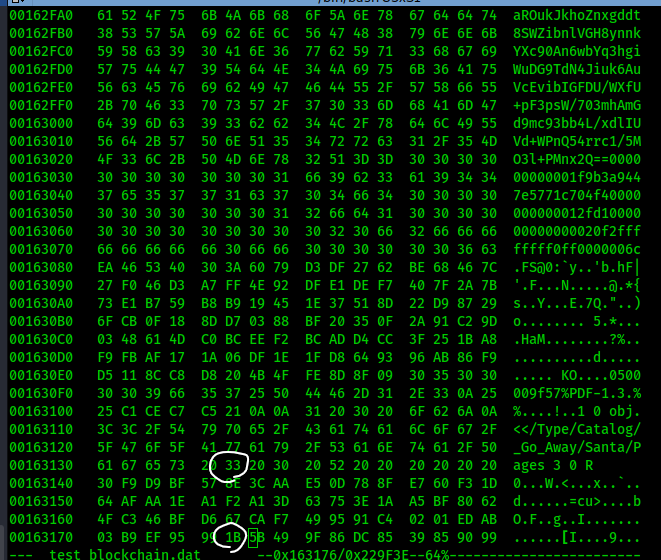
And second, adding to the PDF Byte and subtracting against the corresponding 64th byte:
And there we have it...it should have changed. But how do I know if it worked? In theory, if I modified the blockchain.dat file directly, I could just load it up and validate it with the given code. It should run through each item in the blockchain and validate it. If even one thing is off then the entire chain will not validate, so I can load it up in the same manner I did previously:

YES!
All I need to do now is get the sha256 hash of Jack's original block within the blockchain. And since I know it's block 1010 in the blockchain.dat file, I can execute a few lines of python to dump the result!
import hashlib
from naughty_nice import *
c = Chain(load=True, filename='./test_blockchain.dat')
with open("./official_public.pem", "rb") as f:
pk = RSA.importKey(f.read())
# Make sure it's valid before anything else
assert c.verify_chain(pk)
# Dump the hash!
print(hashlib.sha256(nc.blocks[1010].block_data_signed()).hexdigest())
The result of the above: fff054f33c2134e0230efb29dad515064ac97aa8c68d33c58c01213a0d408afb